zensols.edusenti package#
Submodules#
zensols.edusenti.app#
Pretraining and sentiment student to instructor review sentiment corpora and analysis.
- class zensols.edusenti.app.Application(unpacker)[source]#
Bases:
NLPClassifyPackedModelApplicationClassifies sentiment in Albanian.
- CLASS_INSPECTOR = {}#
- __init__(unpacker)#
zensols.edusenti.cli#
Command line entry point to the application.
- class zensols.edusenti.cli.ApplicationFactory(*args, **kwargs)[source]#
Bases:
ApplicationFactory
zensols.edusenti.domain#
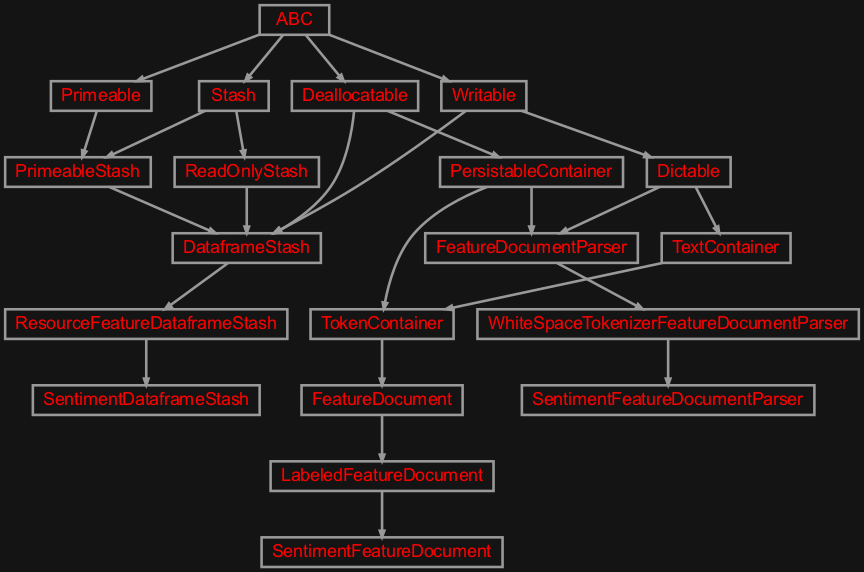
Contains domain and container and utility classes to parse read the corpus.
- class zensols.edusenti.domain.SentimentDataframeStash(dataframe_path, installer, resource, lang, labels)[source]#
Bases:
ResourceFeatureDataframeStashCreate the dataframe by reading the sentiment sentences from the corpus files.
- __init__(dataframe_path, installer, resource, lang, labels)#
- class zensols.edusenti.domain.SentimentFeatureDocument(sents, text=None, spacy_doc=None, label=None, pred=None, softmax_logit=None, topic='none', emotion='none')[source]#
Bases:
LabeledFeatureDocumentA feature document that contains the topic (i.e. subject) and emotion (i.e. joy, fear, etc) of the corresponding sentence(s). This document usually has one sentence per the corpus, but can have more if the language parser chunks it as such.
- __init__(sents, text=None, spacy_doc=None, label=None, pred=None, softmax_logit=None, topic='none', emotion='none')#
-
emotion:
str= 'none'# The emotion of the reveiw (i.e. joy, fear, surpise, etc). Default to
nonefor predictions.
-
topic:
str= 'none'# The subject of the review (i.e. project, instruction, general, etc). Default to
nonefor predictions.
- write(depth=0, writer=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>)[source]#
Write the document and optionally sentence features.
- Parameters:
n_sents – the number of sentences to write
n_tokens – the number of tokens to print across all sentences
include_original – whether to include the original text
include_normalized – whether to include the normalized text
- class zensols.edusenti.domain.SentimentFeatureDocumentParser(*args, **kwargs)[source]#
Bases:
WhiteSpaceTokenizerFeatureDocumentParserA white space tokenizer that sets all the parameters of the spaCy tokenizer to simplify the configuration.